
Lessons learned from ..
.. two orders of magnitude

Let me start with a question: What is crucial difference between the two plots below?
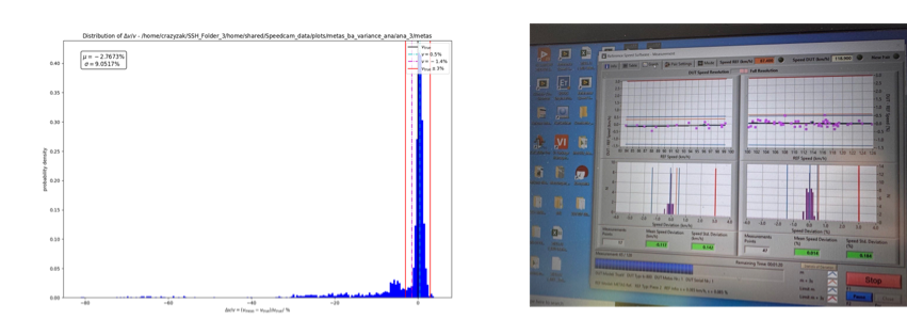
OK, I agree that it is hard to see, so let me zoom in for you into the relevant part of the image:
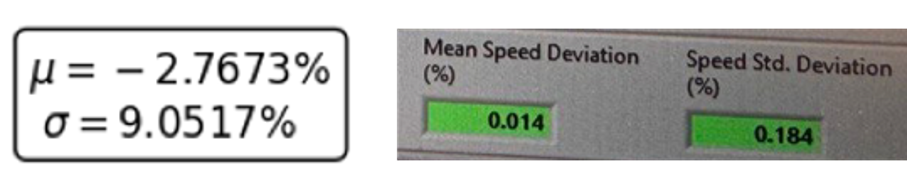
What you can see here are basically two orders of magnitude of improvement in performance in the tests that we conducted back at ROADIA (and later with Breuer). We continuously compared the accuracy of our product in the making with the values from the reference instrument of the certification authorities. The image on the left shows the first test that we conducted in December ‘21 and the image on the right the tests that we did in July ‘24.
It took us 2 years longer than expected, 1 year longer than needed if stars had aligned better, (and an insolvency) but what’s done is done. Looking back on the tremendous work that has been done and all the blood, sweat and – very literally – tears, I thought that it might be a good point in time to write down some key reflections from “two orders of magnitude”:
Product = O(10)x Prototype
I will start again with two images. On the left side you can see our first real-time prototype that we finished in 2021 and on the left hand side, the device that is close to product readiness and was used to measure the impressive progress shown above.

Now, after witnessing the development of both, I tried to estimate the total amount of efforts that went into building the first prototype and then going from the prototype towards a production ready device.
My estimate is that it takes about 10x to 30x man-hours or capital effort to go through this process compared to the efforts of building the first proof-of-concept (PoC).
Back in 2018, when working in the aviation industry and being in close exchange with the automotive industry, I asked myself “why do they have 30.000 people working on this product development and a project manager for seemingly every single item on the bills-of-material (BOM)”? Now, it seems much clearer why: If you need to make sure that something works reliable not once or twice but every single time a customer touches it, than every single little component is a project on its own; and if you have O(10k) of components in your product, you will need roughly this amount of project managers and technical experts, for each part at least one of each.
So, if you like to have a rule of thumb: Make your best realistic to conservative estimate on efforts and multiply it at least by three.
I felt into the trap of making an optimistic to realistic estimate and only applying a factor of two at most. What gives me some mental relief, however, is the fact that this seems to be rather the norm than the exception: Take the Boeing 787 development as one example: Its development costs were estimated at $7 billion in the beginning. In the end the costs were $32 billion. And remember it is BOEING: These people have been developing, building and delivering aircraft since world war I ! Another great example is the construction of the new airport in Berlin which was estimated at €2 billion and had cost of €7 billion by its opening – and building an airport is actually an “off-the-shelf” product (admittingly a complex one). And list could go on for long.
I suppose the pattern that we can observe in this context again and again is the classic “salami tactics”: Pitching the pessimistic or realistic scenario with margin, the project would never get approved (or in case of start-ups: funded). Hence, the typical way out is to pitch the best-case scenario (with little margin) to get people excited and then play the “sunken cost fallacy card”: Make people throw good money after what seemed to be good money if things don’t go according to plan.
If you have been on both sides of the table, e.g. being a CEO, investor or product owner (pushing for fast delivery and go-to-market) as well as CTO, VP of engineering or developer (trying to build to last), you realize how strange this thing actually is: Most people who are in charge of “calling the shots” (i.e. setting the timelines and priorities) actually started as people who were responsible for delivery at some point. Being asked “how long” things take, one would try to give a realistic answer and then remember how project deadlines would be slashed to “unrealistic timelines” to match the expectations from higher managements, shareholders or markets. Being pissed off hard by this, one would promise to do better once in charge. Then, once in charge to set timelines etc., the people promised to do better, tend to repeat what they intended to do different.
And this leads us to a central paradox: Given that after some years in business everybody knows how the game is played; one would think that we should try to opt out to do better. However, as the examples above show, this hardly seems to happen; and while there is a lot of talk about transparency, as managers we tend to push our teams to create unrealistic timelines and ignore the lessons that we learned previously ourselves; and as (individual) contributors we tend to ignore our individual responsibility to stick to deadlines that we committed to.
Nevertheless, I think it would be too easy to say that “managers should just plan better and have more realistic expectations” for two reasons:
Firstly, always in life, we play multiple roles at the same time. We are not only contributors, or middle managers but also customers of goods and services and shareholders. In the latter roles, we ourselves put expectations and pressure on the organizations and consequently the people who are involved in the fulfillment. Thus, each of us contributes to create expectations and put pressure on “tighter deadlines” (You expect to have your online purchase delivered tomorrow, not in a week – don’t you?).
Secondly, the German Proverb “Ein Projekt ist wie ein Gas, es nimmt den ganzen Raum ein, dem man ihm zur Verfügung stellt.“ (A project is like a gas, it takes all the space that is offered.) has some true core to it. It basically means that having no deadlines at all, is similarly a problem as having too tight ones.
Unfortunately, there seem to be no magic recipe to this problem and finding the right balance is a central challenge for each ambitious venture.
The important thing to accept and remember is: Whatever your estimate is, it will probably take longer and cost more. This should be the main premise of your planning. Probably, the single best thing that you can do is to find the right people to endure this with you ... I will come to this in a follow-up text.
Chicken and Egg Problem
Building a complex product, where hardware as well as software have to be developed from scratch poses a challenge on its own: The software guys expect the hardware to work in order to implement and test their stuff, the hardware guys expect the software to work in order to test the hardware in proper environment. It gets especially tricky if a problem on the software side is either very hard to solve (or even unsolvable) without a change in the hardware design - creating a circular dependency.
This seems like a deadlock situation which can be resolved in two ways:
a) Make a large plan and work stringently sequential instead of working in parallel.
b) Try to develop both things as independent of each other as possible in order not to block the development of each individual part.
As solution a) enlarges timelines by quite a lot, we opted for b) and decided to work in “iteration cycles” which in itself posed a couple of issues:
The first issue is that the iteration speed of hardware and software is somewhat different, even the iteration speeds within the different hardware and software components are different. This means that some people will either be under extreme pressure to deliver by the end of each iteration cycle (or sprint in “AGILE”-terms) while others will idle. The text-book rule would now be “let the earlybirds help the others” but unfortunately the skill stack of a mechanical design engineer and computer vision expert are too far off to effectively help each other. To my personal surprise, in some cases the blocker is not even the skillset but also the mere attitude of people saying, “but I was hired for doing something else”.
The solution or – better to say – the way of work that evolved out of this problem was not to have a project wide “iteration cycle” but effectively have many subsystem iteration cycles run in parallel.
The high parallelization of iteration cycles resulted in a second issue: In a growing disconnect between the teams and eventually the people. In turn this makes additional management efforts necessary to help everybody on the project to understand what the other people are doing as well as to connect in-between each other on a personal level.
And it resulted in a third issue: A challenging merge queue. Who should come first? Who should rebase, who not? What is the most blocking thing in the pipeline? Your main job as a technical leader becomes to identify the issue that is blocking the largest number of iteration cycles and see how it can be merged quickest without jeopardizing the overall project quality [1].
In summary, I feel that running things in high parallelization helps to maintain speed at the costs of non-neglectable management overhead to keep the parts together – but I guess if managers are not in a company for this, then what for?
Building infrastructure is > 80 % of efforts
What is infrastructure? Let’s say that you want to produce cars. It’s close to impossible to just start to build cars, you need to invest into a car factory, and you need to invest heavily. The factory and the whole supply chain, as well as its proper management, is the necessary infrastructure to produce cars. As Elon once put it: “Production hell” or in other words: The real challenge is to build the machines that build the machines.
What is true for production similarly applies to the step before: Product development.
At the point where we switched from “initial prototyping” to building a robust software stack that can be used for a product on the market, we started to build tests for any new feature that was added, for any part of code that was substantially refactored or for any functional bug that was fixed. I would estimate that this increased the time for each pull request (PR) to be merged by roughly 50 %. You can regard this as part of building the “test-infrastructure”.
However, this is only a part of the test infrastructure. Another major part is your git repository that needs to to be configured to run automatic tests and its configuration continuously updated with a growing number of automated tests. In our case, we worked on standalone, embedded devices that have to be integrated into git, maintained constantly connected the internet and have a defined state so that running the same test on two different devices results in the same output.
And again it doesn’t stop here. Developing algorithms and testing their accuracy means two things: a) Having labeled data. b) Having a way to run the algorithm on the data automatically and check that the algorithm’s main KPIs in order to make sure that changes to the code (or the hardware design (!)) really deliver improvements and not otherwise. The effort to build all of this is again effort that do not represent a feature of the actual product but an unavoidable necessity to build the actual features.
And on top of this you have the “very generic” infrastructure that we take usually for granted – such as good IT-infrastructure or a descent work place with the necessary tools.
Add all of this together (and I am sure, that I forgot a couple of essential things in my list above), you can easily see how this can be > 80 % of total effort. The important takeaway from this is that, if you think that you need 3 engineers to build your system, probably you will need at least 6 or rather 8 taking into account all the infrastructure overhead; or if you stick to only 3 people, those 3 will have to work for sufficiently longer than anticipated.
If you want an extreme example of this, think of all the effort it took to build the large hadron collider (about $5 billion) compared to the effort it took Paul Higgs to write his famous paper.
Hard to build or hard to sell?
When making an assessment to a new product or more generally speaking a new business idea one usually has to evaluate two things first: The product risk and the market risk.
In simple terms the product risk is how sure you are about answer the question “Is it possible to build the intended product or service?” and the market risk is about how sure you are about the question “Does somebody want to pay for the product or service that we intend to offer?”.
Another way to think about it is: Who has to work harder to get the business running? The engineering or sales department? If the sales department is able to sell apples for the price of diamonds, then life is pretty easy for engineering. In contrast, if the engineering department can built something remarkable, sales will have an easy game [2].
Let’s think about some seemingly extreme but for that reason clear examples: If you are able to build a fusion reactor, a warp drive or a device that could beam people between two points on the planet, the market risk is roughly 0 but the product risk is arbitrarily high [3]. On the other side of spectrum, we could think about mobile apps or movies. The product risk is close to 0, as we know for sure that these things can be made but it is quite unsure if the market is going to accept them or not.
For most business ideas and products, it is however, not as black and white. There will be some market risk, and some product risk involved. Even with the best research that one can do, assumptions are unavoidable and only step by step such can be validated or disproved.
Given all the things written above, you might imagine that we underestimated the product risk but to our big surprise overestimated the market risk.
Looking back, it still feels astonishing to me how hard both things are to estimate upfront and what particular approach one could take to get a better grasp on both. So far, the best thing that seems to work is to “do it and find out the details along the way” but again that is not that different from what we did last time.
Indeed, there a couple things more that I would like to add to the list here but when I started to write them down, I felt that they would deserve a post on their own, so that I decided to cover them in separate text later.
Be ready for a “lessons learned from two orders of magnitude”-series of post to appear soon.
[1] It’s an interesting observation, that given a particular constellation of things that even people who are in similar roles start to push their peers to deliver things faster, so they can move on with their own agenda.
[2] That is at least what I feel many engineers believe as they have the most extreme cases in their mind. Reality is often different from this scenario: If the engineers are to build something truly remarkable, usually the hard sales part happens upfront: Namely, raising the necessary funds to finance the engineering, which is in fact selling the idea and the confidence in the team behind it.
[3] At least for the latter two cases. For the first case (the fusion case), it can be estimated in tens of billions as it is roughly the amount of money that was publicly and privately invested into the topic until now with the expectation to make bring it to productivity.